
Artificial intelligence chatbots are intelligent virtual assistants that employ advanced algorithms to understand and interpret human language in real time. AI chatbots mark a shift from scripted customer service interactions to dynamic, effective engagement. This article will explain types of AI chatbots, their architecture, how they function, and their practical benefits across multiple industries.
What Is an AI Chatbot?
An AI chatbot is a software program that uses artificial intelligence to engage in conversations with humans. AI chatbots understand spoken or written human language and respond like a real person. They adapt and learn from interactions without the need for human intervention. Examples include using Facebook Messenger to order from Dominos Pizza, house purchase information and virtual tours based on chat interactions from Home Boutique’s chatbot, and Siri and Alexa, conversational chatbots that can control smart homes, answer questions, and play music based on speech input.
Artificial intelligence chatbots are now an essential part of modern business. Unlike non-AI customer service technologies, they excel in providing personalized, real-time responses to users’ questions. For example, AI chatbots can assist with product selections, schedule appointments, and handle various tasks like customer service inquiries and supply chain optimization that previously required human intervention. This is transforming the way that businesses engage with their audiences, as well as aspects of everyday life, such as drafting personal emails and facilitating online shopping experiences.
Here’s an example of an AI chatbot interaction in a commercial beauty customer service context:

What Types of Chatbots Are There?
Most AI chatbots can be categorized into two types: rule-based chatbots and machine learning-powered chatbots.
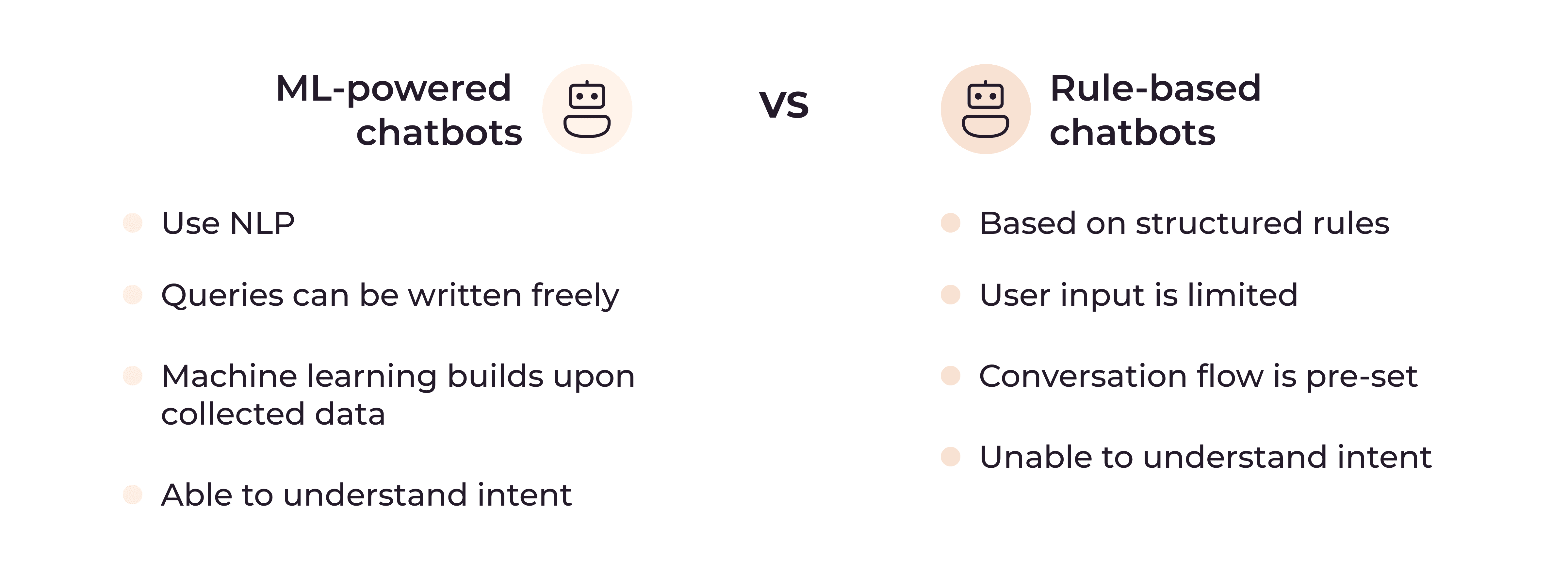
Rule-Based Chatbots
Rule-based chatbots operate on preprogrammed commands and follow a set conversation flow, relying on specific inputs to generate responses. Many of these bots are not AI-based and thus don’t adapt or learn from user interactions; their functionality is confined to the rules and pathways defined during their development.
A non-AI rule-based chatbot on a bank’s website might guide users through a limited list of options like “Check my balance” or “Find an ATM.” If a user deviates from these predefined commands, the bot may respond with an error, as it’s limited to its pre-set rules and cannot adapt to unexpected inputs.
However, AI rule-based chatbots exceed traditional rule-based chatbot performance by using artificial intelligence to learn from user interactions and adapt their responses accordingly. This allows them to provide more personalized and relevant responses, which can lead to a better customer experience. An AI rule-based chatbot would be able to understand and respond to a wider range of queries than a standard rule-based chatbot, even if they are not explicitly included in its rule set. For example, if a user asks the AI chatbot “How can I open a new account for my teenager?”, the chatbot would be able to understand the intent of the query and provide a relevant response, even if this is not a predefined command. This allows AI rule-based chatbots to answer more complex and nuanced queries, improving customer satisfaction and reducing the need for human customer service.
Machine Learning-Powered Chatbots
Machine learning-powered chatbots, also known as conversational AI chatbots, are more dynamic and sophisticated than rule-based chatbots. By leveraging technologies like natural language processing (NLP,) sequence-to-sequence (seq2seq) models, and deep learning algorithms, these chatbots understand and interpret human language. They can engage in two-way dialogues, learning and adapting from interactions to respond in original, complete sentences and provide more human-like conversations.
For example, in the same bank website context, a chatbot could answer questions about investment products, help users with complex, individualized financial transactions, and identify and resolve potential issues before they escalate. For example, if historical data shows that customers performing a certain action often need customer service help with a specific element—say, they struggle to find their account number on a banking app—the ML-powered chatbot could explain how to find the account number upfront, anticipating the problem before it occurs. It could even detect tone and respond appropriately, for example, by apologizing to a customer expressing frustration. In this way, ML-powered chatbots offer an experience that can be challenging to differentiate them from a genuine human making conversation.
Specialized Chatbots
AI chatbots can also be trained for specialized functions or on particular datasets. They can break down user queries into entities and intents, detecting specific keywords to take appropriate actions. For example, in an e-commerce setting, if a customer inputs “I want to buy a bag,” the bot will recognize the intent and provide options for purchasing bags on the business’ website.
Who Uses AI Chatbots? AI Chatbot Use Cases
Currently, AI chatbots are best known in applications like Siri, Alexa, Google Assistant, and ChatGPT, providing generic conversational assistance for diverse use cases in personal and professional contexts alike. However, beyond this familiar use, AI chatbots have found many diverse and specific uses across industries. These tailored applications are meticulously trained to cater to the particular needs and nuances of different sectors. Here’s a glimpse at just a few of them:
- Automotive sector: A small chain of car dealerships might use artificial intelligence chatbots to assist customers in locating the perfect car from their cross-country inventory. By interpreting the customer’s needs through conversation, the chatbot can filter through options and provide detailed recommendations.
- Healthcare industry: AI chatbots in hospitals can expedite patient care by answering medical inquiries and scheduling appointments with specialists. For example, a mental health clinic might use a chatbot to conduct initial assessments, directing patients quickly and accurately to the right expert for further consultation.
- Smartphone repair businesses: A troubleshooting AI chatbot can offer immediate assistance with basic home troubleshooting for smartphones (or other electronic devices.) If the issue requires in-person attention, the chatbot can book an appointment with a skilled technician in-store. This frees up technician time, reducing wait times for customers.
- Travel agencies: In the travel industry, AI chatbots can act as a personal travel guide, helping users find flights and accommodations, and plan detailed itineraries. A specialized chatbot for adventure tourism could suggest off-the-beaten-path destinations based on a traveler’s preferences or needs, and even make reservations. For example, a traveler in a wheelchair or a family with young children—or any combination of needs—could get tailored travel plans.
- E-commerce for specialty products: A boutique that sells organic skincare products may employ an AI chatbot to help customers choose products tailored to their skin type. By asking a series of questions, the bot could recommend a personalized skincare regimen. The chatbot could additionally account for factors like budget and time spent on the skincare routine, creating an individualized recommendation.
- Financial institutions: Banks and financial services often use AI chatbots to provide real-time assistance with transactions, account inquiries, or investment advice. For example, a credit union might deploy a chatbot designed to help first-time homebuyers understand mortgage options and connect them with a mortgage specialist.
What Is AI Chatbot Architecture?
AI chatbot architecture is the sophisticated structure that allows bots to understand, process, and respond to human inputs. It functions through different layers, each playing a vital role in ensuring seamless communication. Let’s explore the layers in depth, breaking down the components and looking at practical examples.

User Interface (UI) Layer
The UI layer serves as the gateway for user interaction, facilitating both input and output. It includes:
- Voice interaction: This allows communication via voice commands, like asking Google Assistant for directions.
- Text interaction: This supports text-based communication. Facebook Messenger bots, for example, can respond to text queries.
Front-End Systems Layer
The front-end systems layer encompasses the UI layer discussed above, taking its functions one step further by managing the underlying functionality that allows users to interact with the chatbot, handling user input, generating responses, and tracking user sessions on platforms like Facebook Messenger, WhatsApp Business and Google Hangouts. This layer also includes the logic that determines how the chatbot behaves, such as how it responds to different user prompts or how it escalates issues to human customer support. Here, NLP plays a significant role by interpreting human language into a form computers understand. Practically, this is done through various techniques, including:
- Tokenization, which breaks user input into tokens, identifying key words. For example, “I like to play basketball,” would be tokenized into the following tokens: “I,” “like,” “to,” “play,” and “basketball.”
- Entity recognition, which identifies entities like “New York” in a travel query, for example.
- Sentiment analysis, which analyzes the emotion behind words, such as anger in a frustrated customer service chatbot interaction.
Conversation Management Layer
This layer ensures coherent and logical conversation flow. Here, two processes are at play:
- Dialogue management, which controls the direction of conversation by asking clarifying questions or providing relevant responses.
- Session management, which keeps track of ongoing conversations, like remembering past shopping interactions.
Integration Layer
This layer links the chatbot with external systems and databases, managing the flow of data between the chatbot and these systems by performing:
- API integration, which connects to third-party services, such as fetching flight details from an airline.
- Database retrieval, which pulls information from internal databases, like accessing a patient’s medical history.
- Routing user traffic requests through the Node.js server/traffic server to link the user’s queries to the specific functions and databases needed to provide accurate responses.
Learning and Large Language Models (LLMs) Layer
The integration of learning mechanisms and large language models (LLMs) within the chatbot architecture adds sophistication and flexibility. These two components are considered a single layer because they work together to process and generate text.
Learning
Learning mechanisms enable adaptive interactions and personalized responses. Here’s how they function:
- User behavior analytics (UBA): This observes user actions and adapts to them. For example, a music recommendation bot might suggest songs based on a user’s past listening habits.
- Adaptive learning: This enables the chatbot to adjust its behavior over time, such as a tutoring bot that adjusts the difficulty of questions based on a student’s performance.
Large Language Models (LLMs)
LLMs are specialized components designed to understand and generate nuanced text by analyzing vast datasets, thereby excelling at tasks like contextual conversation and content summarization. Here’s how they work:
- Q&A sessions: LLMs enable detailed question-and-answer interactions, like pulling specific product details from a database.
- Toxic comment detection: They can identify harmful or inappropriate comments, ensuring a safe community environment.
- Language translations: LLMs facilitate seamless communication across various languages, bridging language barriers.
- Auto-compilation of commands: They simplify the development process by automatically converting small pieces of code called snippets into a format that the computer can run, eliminating the need for developers to perform this step manually.
Custom Integrations and Question Answering System Layer
Finally, the custom integrations and the Question Answering system layer focuses on aligning the chatbot with your business needs. Custom integrations link the bot to essential tools like CRM and payment apps, enhancing its capabilities. Simultaneously, the Question Answering system answers frequently asked questions through both manual and automated training, enabling faster and more thorough customer interactions.
How AI Chatbots Work

AI chatbots operate through a multi-stage process. While the general flow of this process is applicable to most ML and AI processes, some of the techniques in this process—such as natural language processing, contextual understanding, and real-time conversational analytics—are unique to AI chatbots.
Input
Input channels include APIs and direct integration with platforms such as WhatsApp and Instagram. The input stage is initiated when a user submits a textual query; it involves preprocessing steps like lowercasing and punctuation removal. These preprocessing steps standardize the text, making it easier for the chatbot to understand and process the user’s request, thereby improving the speed and accuracy of the chatbot’s responses.
In a customer service scenario, a user may submit a request via a website chat interface, which is then processed by the chatbot’s input layer. This is often handled through specific web frameworks like Django or Flask. These frameworks simplify the routing of user requests to the appropriate processing logic, reducing the time and computational resources needed to handle each customer query.
Analysis
The analysis stage combines pattern and intent matching to interpret user queries accurately and offer relevant responses.
Pattern Matching
The analysis and pattern matching process within AI chatbots encompasses a series of steps that enable the understanding of user input. For example, pattern matching in a weather chatbot identifies the keyword “weather” and the location “Paris” by scanning the user’s input for these predefined terms, allowing the chatbot to generate a tailored response about current weather conditions in that city.
Pattern matching steps include both AI chatbot-specific techniques, such as intent matching with algorithms, and general AI language processing techniques. The latter can include natural language understanding (NLU,) entity recognition (NER,) and part-of-speech tagging (POS,) which contribute to language comprehension. NER identifies entities like names, dates, and locations, while POS tagging identifies grammatical components.
Intent Matching
The concept of intent matching is specific to AI chatbots. It involves mapping user input to a predefined database of intents or actions—like genre sorting by user goal.
For instance, when a user inputs “Find flights to Cape Town” into a travel chatbot, NLU processes the words and NER identifies “New York” as a location. Intent matching algorithms then take the process a step further, connecting the intent (“Find flights”) with relevant flight options in the chatbot’s database. This tailored analysis ensures effective user engagement and meaningful interactions with AI chatbots.
Output
The output stage consists of natural language generation (NLG) algorithms that form a coherent response from processed data. This might involve using rule-based systems, machine learning models like random forest, or deep learning techniques like sequence-to-sequence models. The selected algorithms build a response that aligns with the analyzed intent.
In an e-commerce setting, these algorithms would consult product databases and apply logic to provide information about a specific item’s availability, price, and other details.
Continued Learning
In the learning phase, convolutional neural networks (CNNs) analyze spatial data like images, identifying patterns such as shapes or colors, while recurrent neural networks (RNNs) examine sequential data like sentences, wherein they recognize the order of words. Through iterative training on new data, these artificial neural networks fine-tune their internal parameters, thereby improving the chatbot’s ability to provide more accurate and relevant responses in future interactions.
Reinforcement learning algorithms like Q-learning or deep Q networks (DQN) allow the chatbot to optimize responses by fine-tuning its responses through user feedback. When the chatbot interacts with users and receives feedback on the quality of its responses, the algorithms work to adjust its future responses accordingly to provide more accurate and relevant information over time. In an educational application, a chatbot might employ these techniques to adapt to individual students’ learning paces and preferences.
Challenges and Benefits of AI Chatbots for Businesses
AI chatbots present both opportunities and challenges for businesses.
Benefits
- 24/7 availability, providing instant responses and thus increasing customer satisfaction while reducing overhead costs.
- Handling multiple queries simultaneously, offering efficiency and scale without additional staffing.
- Automation of repetitive tasks, freeing up human resources for more complex jobs.
- Streamlined order processes, making ordering easier for customers and businesses.
- Natural conversations and tailored experiences, paving the way for upselling and cross-selling.
Challenges
- Up-to-date data collection and accuracy, which can’t always be guaranteed by chatbots.
- Difficulty understanding nuanced human emotions, leading to less effective interactions.
- Algorithmic limitations, hindering chatbots from effectively resolving intricate or multi-layered queries.
Conclusion
AI chatbots offer an exciting opportunity to enhance customer interactions and business efficiency. In a world where time and personalization are key, chatbots provide a new way to engage customers 24/7. The power of AI chatbots lies in their potential to create authentic, continuous relationships with customers.
Explore the future of NLP with Gcore’s AI IPU Cloud and AI GPU Cloud Platforms, two advanced architectures designed to support every stage of your AI journey. From building to training to deployment, the Gcore’s AI IPU and GPU cloud infrastructures are tailored to enhance human-machine communication, interpret unstructured text, accelerate machine learning, and impact businesses through analytics and chatbots. The AI IPU Cloud platform is optimized for deep learning, customizable to support most setups for inference, and is the industry standard for ML. On the other hand, the AI GPU Cloud platform is better suited for LLMs, with vast parallel processing capabilities specifically for graph computing to maximize potential of common ML frameworks like Tensorflow.
Find out which solution works best for your AI requirements.
Related articles

How AI is reshaping the future of interactive streaming
Interactive streaming is entering a new era. Artificial intelligence is changing how live content is created, delivered, and experienced. Advances in real-time avatars, voice synthesis, deepfake rendering, and ultra-low-latency delivery are giving rise to new formats and expectations.Viewers don’t want to be passive audiences anymore. They want to interact, influence, and participate. For platforms that want to lead, the stakes are growing: innovate now, or fall behind.At Gcore, we support this shift with global streaming infrastructure built to handle responsive, AI-driven content at scale. This article explores how real-time interactivity is evolving and how you can prepare for what’s next.A new era for live contentStreaming used to mean watching someone else perform. Today, it’s becoming a conversation between the creator and the viewer. AI tools are making live content more reactive and personalized. A cooking show host can take ingredient requests from the audience and generate live recipes. A language tutor can assess student pronunciation and adjust the lesson plan on the spot. These aren’t speculative use cases—they’re already being piloted.Traditional cameras and presenters are no longer required. Some creators now use entirely digital hosts, powered by motion capture and generative AI. They can stream with multiple personas, switch backgrounds on command, or pause for mid-session translations. This evolution is not about replacing humans but creating new ways to engage that scale across time zones, languages, and platforms.Creating virtual influencersVirtual influencers are digital characters designed to build audiences, promote products, and hold conversations with followers. Unlike human influencers, they don’t get tired, change jobs, or need extensive re-shoots when messaging changes. They’re fully programmable, and the most successful ones are backed by teams of writers, animators, and brand strategists.For example, a skincare company might launch a virtual influencer with a consistent tone, recognizable look, and 24/7 availability. This persona could host product tutorials in the morning, respond to DMs during the day, and livestream reactions to customer feedback at night—all in the local language of the audience.These characters are not limited to influencer marketing. A virtual celebrity might appear as a guest at a live product launch or provide commentary during a sports event. The point is consistency, scalability, and control. Gcore’s global delivery network ensures these digital personas perform without delay, wherever the audience is located.Real-time avatars and AI-generated personasReal-time avatars use motion capture and emotion detection to mimic human behavior with digital models. A fitness instructor can appear as a stylized avatar while tracking their own real movements. A virtual talk show host can gesture, smile, or pause in response to viewer comments. These avatars do more than just look the part—they respond dynamically.AI-generated personas build on this foundation with language generation and decision-making. For instance, an edtech company could deploy a digital tutor that asks learners comprehension questions and adapts its tone based on their engagement level. In entertainment, a music artist might perform live as a virtual character that reflects audience mood through color shifts, dance patterns, or facial expression.These experiences require ultra-low latency. If the avatar lags, the illusion collapses. Gcore’s infrastructure supports the real-time input-output loop needed to make digital characters feel present and responsive.Deepfake technology for creative storytellingDeepfakes are often associated with misinformation, but the same tools can be used to build engaging, high-integrity content. The technology enables face-swapping, voice cloning, and character animation, all of which are powerful in live formats.A museum might use deepfake avatars of historical figures for interactive educational sessions. Visitors could ask questions, and Abraham Lincoln or Golda Meir might respond with historically grounded answers in real time. A brand could create a fictional spokesperson who evolves over time, appearing in product demos, ads, and livestreams. Deepfake technology also allows multilingual content without re-recording—the speaker’s lip movements and tone are modified to match each language.These applications raise legitimate ethical questions. Gcore’s streaming infrastructure includes controls to ensure the source and integrity of AI-generated content are traceable and secure. We provide the technical foundation that enables deepfake use cases without compromising trust.Synthetic voices and personalized audioAudio is often overlooked in discussions about AI streaming, but it’s just as important as video. Synthetic voices today can express subtle emotions and match speaking styles. They can whisper, shout, pause for dramatic effect, and even mimic regional accents.Let’s consider a news platform that offers interactive daily briefings. Viewers choose their preferred language, delivery style (casual, serious, humorous), and even the voice profile. The AI generates a personalized broadcast on the fly. In gaming, synthetic characters can offer encouragement, warn about strategy mistakes, or narrate progress—all without human voice actors.Gcore’s streaming infrastructure ensures that synthetic voice outputs are tightly synchronized with video, so users don’t experience out-of-sync dialogue or lag during back-and-forth exchanges.Increasing interactivity through feedback and participationInteractivity in streaming now goes far beyond comments or emoji reactions. It includes live polls that influence story outcomes, branching narratives based on audience behavior, and user-generated content layered into the broadcast.For example, a live talent show might allow viewers to suggest challenges mid-broadcast. An online classroom could let students vote on the next topic. A product launch might include a real-time Q&A where the host pulls questions from chat and answers them in the moment.All of these use cases rely on real-time data processing, behavior tracking, and adaptive rendering. Gcore’s platform handles the underlying complexity so that creators can focus on building experiences, not infrastructure.Why low latency is criticalInteractive content only works if it feels immediate. A delay of even a second can break immersion, especially when users are trying to influence the outcome or receive a response. Low latency is essential for real-time gaming, sports, interviews, and educational formats.A live trivia game with hundreds of participants won’t retain users if there’s a lag between the question appearing and the timer starting. A remote surgery training session won’t work if the avatar’s responses trail behind the mentor’s instructions. In each of these cases, timing is everything.Gcore Video Streaming minimizes buffering, supports high-resolution streams, and synchronizes data flows to keep participants engaged. Our infrastructure is built to support high-throughput, globally distributed audiences with the responsiveness that interactive formats demand.Preparing for what’s nextAI-generated content is no longer a novelty. It’s becoming a standard feature of modern streaming strategies. Whether you’re building a platform that features virtual influencers, immersive avatars, or interactive educational streams, the foundation matters. That foundation is infrastructure.If you’re planning the next generation of live content, we’re ready to help you bring it to life. At Gcore, we provide the performance, scale, and security to launch these experiences with confidence. Our streaming solutions are designed to support real-time content generation, audience interaction, and global delivery without compromise.Want to see interactive streaming in action? Learn how fan.at used Gcore Video Streaming to deliver ultra-low-latency streams and boost fan engagement with real-time features.Read the case study

What are virtual machines?
A virtual machine (VM), also called a virtual instance, is a software-based version of a physical computer. Instead of running directly on hardware, a VM operates inside a program that emulates a complete computer system, including a processor, memory, storage, and network connections. This allows multiple VMs to run on a single physical machine, each with its own operating system and applications, as if they were independent computers.VMS are useful because they provide flexibility, isolation, and scalability. Since each VM is self-contained, it can run different operating systems (like Windows, Linux, or macOS) on the same hardware without affecting other VMs or the host machine. This makes them ideal for testing software, running legacy applications, or efficiently using server resources in data centers. Because VMs exist as software, they can be easily copied, moved, or backed up, making them a powerful tool for both individuals and businesses.Read on to learn about types of VMs, their benefits, common use cases, and how to choose the right VM provider for your needs.How do VMs work?A virtual machine (VM) runs inside a program called a hypervisor, which acts as an intermediary between the VM and the actual computer hardware. Every time a VM needs to perform an action—such as running software, accessing storage, or using the processor—the hypervisor intercepts these requests and decides how to allocate resources like CPU power, memory, and disk space. You can think of a hypervisor as an operating system for VMs, managing multiple virtual machines on a single physical computer. Popular hypervisors like VirtualBox and VMware enable users to run multiple operating systems simultaneously while providing strong isolation.Modern hypervisors optimize performance by giving VMs direct access to certain hardware components when possible, reducing the need for constant intervention. However, some level of overhead remains because the hypervisor still needs to manage and coordinate resources efficiently. This means that while VMs can leverage most of the system’s hardware, they can’t use 100% of it, as some processing power is always reserved for managing virtualization itself. This small trade-off is often worth it, as hypervisors keep each VM isolated and secure, preventing one VM from interfering with another.VM layersFigure 1 illustrates the layers of a system virtual machine setup. The layer model can vary depending on the hypervisor. Some hypervisors include a built-in host operating system, while modern hardware offers native virtualization support. Many hypervisors can also manage multiple physical machines and VMs efficiently.VM snapshots are an essential feature in cloud computing, allowing users to quickly restore a virtual machine to a previous state.Figure 1: Layers of system virtual machinesHypervisors that emulate hardware architectures different from what the guest OS expects have a bigger overhead, as they can’t relay commands directly to the hardware without first translating them.VM snapshotsVM snapshots are an essential feature in cloud computing, allowing users to quickly restore a virtual machine to a previous state. The hypervisor can save the complete state of the VM and restore it at a later time to skip the boot process of the guest OS. The hypervisor can also move these snapshots between different physical machines, making the software running in the VM completely independent from the underlying hardware.What are the benefits of using VMs?Virtual machines offer benefits including resource efficiency, isolation, simplified operations, easy migration, faster deployment, cost savings, and security. Let’s look at these one by one.Multiple VMs can run on a single physical machine, making sharing resources between various guest operating systems easier. This is especially important when each guest OS needs to be isolated from the others, such as when they belong to different customers of a cloud service provider. Sharing resources through VMs makes running a server cheaper because you don’t have to buy or rent a whole physical machine, but only parts of it.Since VMs abstract the underlying hardware, they also improve resilience. If the physical machine fails, the hypervisor can perform a quick recovery by moving the snapshots to another machine without changing the guest OS installations to minimize downtime. This abstraction also allows operations teams to focus their deployment efforts on a standardized VM instead of considering different physical implementations.Migrations become easier with snapshots as you can simply move them to a faster machine without modifying the software running inside the VM.Faster deployments are possible because starting a VM is just a software execution instead of setting up a physical server in a data center. While you had to buy a server or rent it for months, with fast deployments, you can now rent a machine for hours, minutes, or even seconds, which allows for quite some savings.Modern CPUs have built-in virtualization features that enable easy resource sharing and enforce the isolation at the hardware layer. This prevents the services of one VM from accessing the resources of the others, improving security compared to running multiple apps inside one OS.Common use cases for VMsVMs have a range of use cases. Let’s look at the most popular ones.Cloud computingThe most popular use case is cloud computing, where VMs allow the secure sharing of the cloud provider’s resources, enabling their customers to rent only the resources they need for the period their workload will run.Software development and testingSoftware development often requires specific tools and libraries that aren’t available on a production machine, so having a development VM with all these tools preinstalled can be helpful. An example is cloud IDEs, which look and feel like regular IDEs but run on a cloud VM. A developer can have one for each project with the required dev tools installed.VMs also allow a developer to set up a machine for software testing that looks exactly like the production environment. Here, the opposite of the development VM is required; it should not have any development tools installed because they would also be missing from production.Cross-platform developmentA special case of the software development use case is cross-platform development. When you implement an app for Android or iOS, for example, you usually don’t do this on a mobile device but on your computer. With VMs, developers can simulate different hardware environments, enabling cross-platform testing without requiring physical devices.Legacy system supportIf the hardware your application requires is no longer in production, a VM might be the only way to keep running your software without reimplementing it. This is similar to the cross-platform development use case, as the VM emulates different hardware, but the difference is that the hardware no longer exists.How to choose the right VM providerTo find the right provider for your workload, the most important factor to assess is your own workload requirements. Ask the following questions and compare the answers to what providers offer.Is your workload compute or I/O-bound?Many workloads, like web servers, are I/O-bound. They don’t make complex calculations but rather simply load data and send it over the network. If you need a VM for an I/O-bound workload, you care more about disk and memory size, as well as network speed.However, compute-heavy workloads, such as AI inference or Kubernetes clusters, require careful resource allocation. If you’re evaluating whether to run Kubernetes on bare metal or VMs, check out our white paper on Bare Metal vs. VM-based Kubernetes Clusters for an in-depth comparison.If your workload is compute-bound instead, you need a high-performance CPU or a GPU and loads of memory. An AI inference engine, for example, only sends a bit of text to a client, but it does many calculations to generate this text.How long will your workload run?Web servers usually run indefinitely, but some workloads only run a few hours or minutes. If you’re doing AI training, you don’t want to pay for your huge VM cluster 24/7 if it only runs a few hours or days a week. In such cases, looking for a provider that allows renting your desired VM type hourly on a pay-as-you-go model might be worthwhile.Certain cloud providers offer cost-effective spot instances, which provide lower prices for non-critical workloads that can tolerate interruptions. These cheap VMs can get shut down at any time with minimal notice, but if your calculations aren’t time-critical, you might save quite a bit of money here.How does your workload scale?Scaling in the cloud is usually done horizontally. That is, by adding more VMs and distributing the work between them. Workloads can have different requirements for when and how fast they must be added and removed.In the AI training example, you might know in advance that one training takes more resources than the other, so you can provision enough VMs when starting. However, a web server workload might change its requirements constantly. Hence, you need a load balancer that automatically scales the instances up and down depending on the number of clients that want to access your service.Do you handle sensitive data?You might have to comply with specific laws and regulations depending on your jurisdiction(s) and industry. This means you must check whether the cloud provider also complies. How secure are their data centers? Where are they located? Do they support encryption in transit, at rest, and in process?What are your reliability requirements?Reliability is a question of costs and, again, of compliance. You might get into financial or regulatory troubles if your workload can’t run. Cloud providers often boast about their guaranteed uptimes, but remember that 99% uptime a year still means over three days of potential downtime. Check your needs and then seek a provider that can meet them reliably.Do you need customer support?If your organization doesn’t have the know-how for operating VMs in the cloud, you might need technical support from the provider. Most cloud providers are self-service, offering you a GUI and an API to manage resources. If your business lacks the resources to operate VMs, seek out a provider that can manage VMs on your behalf.SummaryVMs are a core technology for cloud computing and software development alike. They enable efficient resource sharing, improve security with hardware-enforced guest isolation, and simplify migration and disaster recovery. Choosing the right VM provider starts with understanding your workload requirements, from resource allocation to security and scalability.Maximize cloud efficiency with Gcore Virtual Machines—engineered for high performance, seamless scalability, and enterprise-grade security at competitive pricing. Whether you need to run workloads at scale or deploy applications in seconds, our VMs provide enterprise-grade security, built-in resilience, and optimized resource allocation, all powered by cutting-edge infrastructure. With global reach, fast provisioning, egress traffic included, and pay-as-you-go pricing, you get the scalability and reliability your business needs without overspending. Start your journey with Gcore VMs today and experience cloud computing that’s built for speed, security, and savings.Discover Gcore VMs

How to deploy DeepSeek 70B with Ollama and a Web UI on Gcore Everywhere Inference
Large language models (LLMs) like DeepSeek 70B are revolutionizing industries by enabling more advanced and dynamic conversational AI solutions. Whether you’re looking to build intelligent customer support systems, enhance content generation, or create data-driven applications, deploying and interacting with LLMs has never been more accessible.In this tutorial, we’ll show you exactly how to set up DeepSeek 70B using Ollama and a Web UI on Gcore Everywhere Inference. By the end, you’ll have a fully functional environment where you can easily interact with your custom LLM via a user-friendly interface. This process involves three simple steps: deploying Ollama, deploying the web UI, and configuring the web UI and connecting to Ollama.Let’s get started!Step 1: Deploy OllamaLog in to Gcore Everywhere Inference and select Deploy Custom Model.In the model image field, enter ollama/ollama.Set the Port to 11434.Under Pod Configuration, configure the following:Select GPU-Optimized.Choose a GPU type, such as 1×A100 or 1×H100.Choose a region (e.g., Luxembourg-3).Set an autoscaling policy or use the default settings.Name your deployment (e.g., ollama).Click Deploy model on the right side of the screen.Once deployed, you’ll have an Ollama endpoint ready to serve your model.Step 2: Deploy the Web UI for OllamaGo back to the Gcore Everywhere Inference console and select Deploy Custom Model again.In the Model Image field, enter ghcr.io/open-webui/open-webui:main.Set the Port to 8080.Under Pod Configuration, set:CPU-Optimized.Choose 4 vCPU / 16 GiB RAM.Select the same region as before (e.g., Luxembourg-3).Configure an autoscaling policy or use the default settings.Name your deployment (e.g., webui).Click Deploy model on the right side of the screen.Once deployed, navigate to the Web UI endpoint from the Gcore Customer Portal.Step 3: Configure the Web UIFrom the Web UI endpoint and set up a username and password when prompted.Log in and navigate to the admin panel.Go to Settings → Connections → Disable the OpenAI API integration.In the Ollama API field, enter the endpoint for your Ollama deployment. You can find this in the Gcore Customer Portal. It will look similar to this: https://<your-ollama-deployment>.ai.gcore.dev/.Click Save to confirm your changes.Step 4: Pull and Use DeepSeek 70BOpen the chat section in the Web UI.In the Select a model field, type deepseek-r1:70b.Click Pull to download the model.Wait for the download to complete.Once downloaded, select the model and start chatting!Your AI environment is ready to exploreBy following these steps, you’ve successfully deployed DeepSeek 70B on Gcore Everywhere Inference with Ollama. This setup provides a powerful and user-friendly environment for experimenting with LLMs, prototyping AI-driven features, or integrating advanced conversational AI into your applications.Ready to unlock the full potential of AI? Gcore Everywhere Inference offers outstanding scalability, performance, and support, making it the perfect solution for developers and businesses working with advanced AI models. Dive deeper into our powerful tools and resources by exploring our AI blog and docs.Discover Gcore Everywhere Inference

What is AI inference and how does it work?
Artificial intelligence (AI) inference is what happens when a trained AI model is used to predict outcomes from new, unseen data. While training focuses on learning from historical datasets, inference is about putting that learned knowledge into action—such as identifying production bottlenecks before they happen, converting speech to text, or guiding self-driving cars in real time. This article walks you through the basics of AI inference and shows how to get started.What is AI inference?AI inference is the application phase of artificial intelligence. Once a model has been trained on large datasets, it shifts from “learning mode” to “doing mode”—providing predictions or decisions from new data inputs.For example, an e-commerce platform with a model trained on purchasing behavior uses inference to personalize recommendations for each site visitor. Without re-training from scratch, the model quickly adapts to new browsing patterns and purchasing signals, offering instant, relevant suggestions.By enabling actionable insights, inference is transforming how businesses and technologies function, empowering relevance and instant responsiveness in an increasingly data-driven world.How does AI inference work? A practical guideAI inference has four steps: data preparation, model loading, processing and prediction, and output generation.#1 Data preparationThe first step involves transforming raw input—such as text, images, or numerical data—into a format that the AI model can process. For instance, customer feedback might be converted into numerical representations of words and patterns, or an image could be resized and normalized. Proper data preparation ensures that the AI model can effectively understand and analyze the input. For businesses, this means making sure that input data is clean, well-structured, and formatted according to the model’s requirements.#2 Model loadingOnce the input data is ready, the trained AI model is loaded into memory. This model, equipped with patterns and relationships learned during training, acts as the foundation for predictions and decisions.Businesses must make sure that their infrastructure is capable of quickly loading and deploying AI models, especially during high-demand periods. We simplify this process by providing a high-performance platform with global scalability. Your models are loaded and operational in seconds, whether you’re using a custom model or an open-source one.#3 Processing and predictionIn this step, the prepared data is passed through the model’s neural networks, which apply learned patterns to generate insights or predictions. For example, a customer service AI might analyze incoming messages to determine if they express satisfaction or frustration.The speed and accuracy of this stage depend on access to low-latency infrastructure capable of handling complex calculations. Our edge inference solution means data processing happens close to the source, reducing latency and enabling real-time decision making.#4 Output generationThe final stage translates the model’s mathematical outputs into meaningful insights, such as predictions, labels, or recommendations. These outputs must be integrated into business workflows or customer-facing applications in a way that’s easy to understand and actionable.We help streamline this step by offering APIs and integration tools that allow businesses to seamlessly incorporate inference results into their operations, so outputs are accessible and actionable in real time.A real-life exampleLet’s look at how this works in practice. Consider a retail business implementing AI for inventory management. The system continuously:Receives data from point-of-sale systems and warehouse scannersProcesses this information through trained AI modelsGenerates predictions about future inventory needsAdjusts order quantities and timing automaticallyAll of this happens in milliseconds, making real-time decisions possible. However, the speed and efficiency depend on choosing the right infrastructure for your needs.The technology stack behind inferenceTo make this process work smoothly, specialized computing infrastructure and software need to work together.Computing infrastructureModern AI inference relies on specialized hardware designed to process mathematical operations quickly. While training AI models often requires expensive, high-powered graphics processors (GPUs), inference can run on more cost-effective hardware options:CPUs: Suitable for smaller-scale applicationsEdge devices: For processing data locally on smartphones or IoT devices or other hardware closer to the data source, resulting in low latency and better privacy.Cloud-based inference servers: Designed for handling large-scale operations, enabling centralized processing and flexible scaling.When evaluating computing infrastructure for AI, businesses should prioritize solutions that address latency, scalability, and ease of use. Edge inference capabilities are essential for deploying models closer to end users, which optimizes performance globally even during peak demand. Flexible access to diverse hardware options like GPUs, CPUs, and advanced accelerators ensures adaptability, while user-friendly tools and automated scaling enable seamless management and consistent performance.Software optimizationThe efficiency of inference depends heavily on software optimization. When done right, software optimization ensures that AI applications are fast, responsive, and scalable, making them practical for real-world use.Look for the following to identify a solution that reduces inference processing time and supports optimized results:Model compression and optimization: The computational load is reduced and inference occurs faster—without sacrificing accuracy.Workload distribution and automation: This means that resources are allocated efficiently and cost-effectively.Integration: Look for APIs and tools that connect seamlessly with existing business systems.The future of AI inferenceWe anticipate three major trends for the future of AI inference.First, we’re seeing a dramatic shift toward specialized AI accelerators and custom silicon. New chips are being developed and existing ones optimized specifically for inference workloads. These purpose-built processors are delivering significant improvements in both performance and energy efficiency compared to traditional GPUs. This specialization is making AI inference more cost-effective and environmentally sustainable, particularly for companies running large-scale operations.The second major trend is the emergence of lightweight, efficient models designed specifically for inference. While large language models like GPT-4 showcase the potential of AI, many businesses are finding that smaller, task-specific models can deliver comparable or better results for their particular needs. These “small language models” (SLMs) and domain-adapted models are trained on focused datasets and optimized for specific tasks, making them more practical for real-world deployment. This approach is particularly valuable for edge computing scenarios where computing resources are limited.Finally, the infrastructure for AI inference is becoming more sophisticated and accessible. Advanced orchestration tools are automating the complex process of model deployment, scaling, and monitoring. These platforms can automatically optimize model performance based on factors like latency requirements, cost constraints, and traffic patterns. This automation is making it possible for companies to deploy AI solutions without maintaining large specialized teams of ML engineers.Dive into more of our predictions for AI inference in 2025 and beyond in our dedicated article.Accelerate inference adoption for your businessAI inference is rapidly becoming a differentiator for businesses. By applying trained AI models to new data, companies can make instant predictions, automate decision-making, and optimize operations across industries. However, achieving these benefits depends on having the right infrastructure and expertise behind the scenes. This is where the choice of inference provider plays a critical role. The provider’s infrastructure determines latency, scalability, and overall efficiency, which directly affect business outcomes. A well-equipped provider allows businesses to maximize the value of their AI investments.At Gcore, we are uniquely positioned to meet these needs with our edge inference solution. Leveraging a secure, global network of over 180 points of presence equipped with NVIDIA GPUs, we deliver ultra-fast, low-latency inference capabilities. Intuitively deploy and scale open-source or custom models on our powerful platform that accelerates AI adoption for a competitive edge in an increasingly AI-driven world.Get a complimentary consultation about your AI inference needs

AI model selection simplified: your guide to Gcore-supported model selection
2024 has been an exceptional year for advancements in artificial intelligence (AI). The variety of models has grown significantly, with impressive strides in performance across domains. Whether it’s text or image classification, text and image generation, speech models, or multimodal capabilities, businesses now face the challenge of navigating an ever-expanding catalog of open-source models. Understanding the differences in tasks and metrics targeted by these models is crucial to making informed decisions.At Gcore, we’ve been expanding our model catalog to simplify AI model testing and deployment. As businesses scale their AI applications across various units, identifying the best model for specific tasks becomes critical. For example, some applications, like cancer screening, prioritize accuracy over latency. On the other hand, time-sensitive use cases like fraud detection demand rapid processing, while cost may drive decisions for lightweight applications like chatbot development.This guide provides a comprehensive overview of the AI models supported on the Gcore platform, their characteristics, and their most effective use cases to help you choose the right model for your needs. Our inference solution also supports custom AI models.Large language models (LLMs)LLMs are foundational for applications requiring human-like understanding and generation of text, making them crucial for customer service, research, and educational tools. These models are versatile and cover a range of applications:Text generation (e.g., creative writing, content creation)SummarizationQuestion answeringInstruction following (specific to instruct-tuned models)Sentiment analysisTranslationCode generation and debugging (if fine-tuned for programming tasks)Models supported by GcoreGcore supports the following models for inference, available in the Gcore Customer Portal. Activate them at the click of a button.Model nameProviderParametersKey characteristicsLLaMA-Pro-8BMeta AI8 BillionBalanced trade-off between cost and power, suitable for real-time applications.Llama-3.2-1B-InstructMeta AI1 BillionIdeal for lightweight tasks with minimal computational needs.Llama-3.2-3B-InstructMeta AI3 BillionOffers lower latency for moderate task complexity.Llama-3.1-8B-InstructMeta AI8 BillionOptimized for instruction following.Mistral-7B-Instruct-v0.3Mistral AI7 BillionExcellent for nuanced instruction-based responses.Mistral-Nemo-Instruct-2407Mistral AI & Nvidia7 BillionHigh efficiency with robust instruction-following capabilities.Qwen2.5-7B-InstructQwen7 BillionExcels in multilingual tasks and general-purpose applications.QwQ-32B-PreviewQwen32 BillionSuited for complex, multi-turn conversations and strategic decision-making.Marco-o1AIDC-AI1-5 Billion (est.)Designed for structured and open-ended problem-solving tasks.Business applicationsLLMs play a pivotal role in various business scenarios; choosing the right model will be primarily influenced by task complexity. For lightweight tasks like chatbot development and FAQ automation, models like Llama-3.2-1B-Instruct are highly effective. Medium complexity tasks, including document summarization and multilingual sentiment analysis, can leverage models like Llama-3.2-3B-Instruct and Qwen2.5-7B-Instruct. For high-performance needs like real-time customer service or healthcare diagnostics, models like LLaMA-Pro-8B and Mistral-Nemo-Instruct-2407 provide robust solutions. Complex, large-scale applications, like market forecasting and legal document synthesis, are ideally suited for advanced models like QwQ-32B-Preview. Additionally, specialized solutions for niche industries can benefit from Marco-o1’s unique capabilities.Image generationImage generation models empower industries like entertainment, advertising, and e-commerce to create engaging content that captures the audience’s attention. These models excel in producing creative and high-quality visuals. Key tasks include:Generating photorealistic imagesArtistic rendering (e.g., illustrations, concept art)Image enhancement (e.g., super-resolution, inpainting)Marketing and branding visualsModels supported by GcoreWe currently support six models via the Gcore Customer Portal, or you can bring your own image generation model to our inference platform.Model nameProviderParametersKey characteristicsByteDance/SDXL-LightningByteDance100-400 MillionLightning-fast text-to-image generation with 1024px outputs.stable-cascadeStability AI20M-3.6 BillionWorks on smaller latent spaces for faster and cheaper inference.stable-diffusion-xlStability AI~3.5B Base + 1.2B RefinementPhotorealistic outputs with detailed composition.stable-diffusion-3.5-large-turboStability AI8 BillionBalances high-quality outputs with faster inference.FLUX.1-schnellBlack Forest Labs12 BillionDesigned for fast, local development.FLUX.1-devBlack Forest Labs12 BillionOpen-weight model for non-commercial applications.Business applicationsIn high-quality image generation, models like stable-diffusion-xl and stable-cascade are commonly employed for creating marketing visuals, concept art for gaming, and detailed e-commerce product visualizations. Real-time applications, such as AR/VR customizations and interactive customer tools, benefit from the speed of ByteDance/SDXL-Lightning and FLUX.1-schnell. FLUX.1-dev and stable-diffusion-3.5-large-turbo are excellent options for experimentation and development, allowing startups and enterprises to prototype generative AI workflows cost-effectively. Specialized use cases, such as ultra-high-quality visuals for luxury goods or architectural renders, also find tailored solutions with stable-cascade.Speech recognitionSpeech recognition models are essential for industries like media, healthcare, and education, where transcription accuracy and speed directly impact their efficacy. They facilitate:Accurate speech-to-text transcriptionLow-latency live audio conversionMultilingual speech processing and translationAutomated note-taking and content creationModels supported by GcoreAt Gcore, our inference service supports two Whisper models, as well as custom speech recognition models.Model nameProviderParametersKey characteristicswhisper-large-v3-turboOpenAI809 MillionOptimized for speed with minimal accuracy trade-offs.whisper-large-v3OpenAI1.55 BillionHigh-quality multilingual speech-to-text and translation with reduced error rates.Business applicationsSpeech recognition technology supports a wide range of business functions, all requiring precision and accuracy, delivered at speed. For real-time transcription, whisper-large-v3-turbo is ideal for live captioning and speech analytics applications. High-accuracy tasks, including legal transcription, academic research, and multilingual content localization, leverage the advanced capabilities of whisper-large-v3. These models enable faster, more accurate workflows in sectors where precise audio-to-text conversion is crucial.Multimodal modelsBy bridging text, image, and other data modalities, multimodel models unlock innovative solutions for industries requiring complex data analysis. These models integrate diverse data types for applications in:Image captioningVisual question answeringMultilingual document processingRobotic visionModels supported by GcoreWe currently support the following multimodal models:Model nameProviderParametersKey characteristicsPixtral-12B-2409Mistral AI12 BillionExcels in instruction-following tasks with text and image integration.Qwen2-VL-7B-InstructQwen7 BillionAdvanced visual understanding and multilingual support.Business applicationsFor tasks like image captioning and visual question answering, Pixtral-12B-2409 provides robust capabilities in generating descriptive text and answering questions based on visual content. Qwen2-VL-7B-Instruct supports document analysis and robotic vision, enabling systems to extract insights from documents or understand their physical surroundings. These applications are transformative for industries ranging from digital media to robotics.A multitude of models, supported by GcoreStart developing on the Gcore platform today, leveraging top-tier GPUs for seamless AI model training and deployment. Simplify large-scale, cross-regional AI operations with our inference-at-the-edge solutions, backed by over a decade of CDN expertise.Get started with Inference at the Edge today

How to Run Hugging Face Spaces on Gcore Inference at the Edge
Running machine learning models, especially large-scale models like GPT 3 or BERT, requires a lot of computing power and comes with a lot of latency. This makes real-time applications resource-intensive and challenging to deliver. Running ML models at the edge is a lightweight approach offering significant advantages for latency, privacy, and resource optimization. Gcore Inference at the Edge makes it simple to deploy and manage custom models efficiently, giving you the ability to deploy and scale your favorite Hugging Face models globally in just a few clicks. In this guide, we’ll walk you through how easy it is to harness the power of Gcore’s edge AI infrastructure to deploy a Hugging Face Space model. Whether you’re developing NLP solutions or cutting-edge computer vision applications, deploying at the edge has never been simpler—or more powerful. Step 1: Log In to the Gcore Customer PortalGo to gcore.com and log in to the Gcore Customer Portal. If you don’t yet have an account, go ahead and create one—it’s free. Step 2: Go to Inference at the EdgeIn the Gcore Customer Portal, click Inference at the Edge from the left navigation menu. Then click Deploy custom model. Step 3: Choose a Hugging Face ModelOpen huggingface.com and browse the available models. Select the model you want to deploy. Navigate to the corresponding Hugging Face Space for the model. Click on Files in the Space and locate the Docker option. Copy the Docker image link and startup command from Hugging Face Space. Step 4: Deploy the Model on GcoreReturn to the Gcore Customer Portal deployment page and enter the following details: Model image URL: registry.hf.space/ethux-mistral-pixtral-demo:latest Startup command: python app.py Container port: 7860 Configure the pod as follows: GPU-optimized: 1x L40S vCPUs: 16 RAM: 232GiB For optimal performance, choose any available region for routing placement. Name your deployment and click Deploy.Step 5: Interact with Your ModelOnce the model is up and running, you’ll be provided with an endpoint. You can now interact with the model via this endpoint to test and use your deployed model at the edge.Powerful, Simple AI Deployment with GcoreGcore Inference at the Edge is the future of AI deployment, combining the ease of Hugging Face integration with the robust infrastructure needed for real-time, scalable, and global solutions. By leveraging edge computing, you can optimize model performance and simultaneously futureproof your business in a world that increasingly demands fast, secure, and localized AI applications. Deploying models to the edge allows you to capitalize on real-time insights, improve customer experiences, and outpace your competitors. Whether you’re leading a team of developers or spearheading a new AI initiative, Gcore Inference at the Edge offers the tools you need to innovate at the speed of tomorrow. Explore Gcore Inference at the Edge
Subscribe to our newsletter
Get the latest industry trends, exclusive insights, and Gcore updates delivered straight to your inbox.